Streaming your media with Jinzora gives you quick and easy access to your online music and video collection from any device with a web browser.
Enjoy your media from your PC, notebook, PDA, Smart Phone, Xbox, PS3 or Wii.
Use Jinzora in Jukebox Mode to control a hardware device like your stereo set or Squeezebox and third-party software, including MPD, VLC and Shoutcast.
Pre-installation
Before you can install Jinzora, you must set up a LAMP server first.
#yum install mysql mysql-server httpd php php-mysql php-gd php-imap php-ldap php-odbc php-pear php-xml php-xmlrpc
#service httpd start
#service mysqld start
#mysql_secure_installation (set up root password)
#wget http://downloads.sourceforge.net/jinzora/jz280.tar.gz
#tar zxvf jinzora-3.0.tar.gz
#cd jinzora-3.0
#mv * /var/www/html/jinzora
#cd /var/www/html/jinzora
#sh config.sh
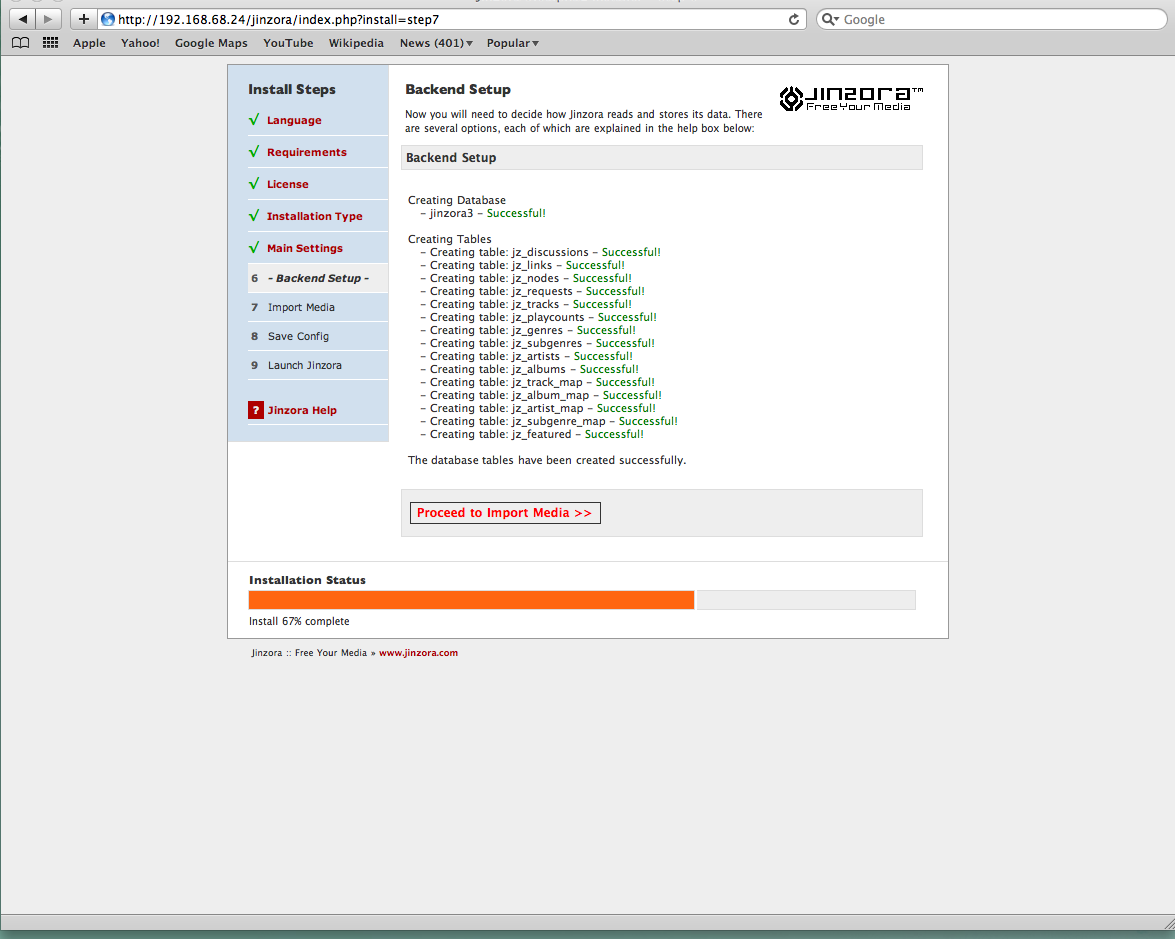
You are now in setup mode.
Please direct your web browser to the directory where you installed Jinzora
and load index.php - you will then be taken through the complete setup
http://yourdomain.com/